T-Eval: Evaluating the Tool Utilization Capability
of Large Language Models Step by Step
Abstract
Large language models (LLM) have achieved remarkable performance on various NLP tasks and are augmented by tools for broader applications. Yet, how to evaluate and analyze the tool utilization capability of LLMs is still under-explored. In contrast to previous works that evaluate models holistically, we comprehensively decompose the tool utilization into multiple sub-processes, including instruction following, planning, reasoning, retrieval, understanding, and review. Based on that, we further introduce T-Eval to evaluate the tool-utilization capability step by step. T-Eval disentangles the tool utilization evaluation into several sub-domains along model capabilities, facilitating the inner understanding of both holistic and isolated competency of LLMs. We conduct extensive experiments on T-Eval and in-depth analysis of various LLMs. T-Eval not only exhibits consistency with the outcome-oriented evaluation but also provides a more fine-grained analysis of the capabilities of LLMs, providing a new perspective in LLM evaluation on tool-utilization ability.
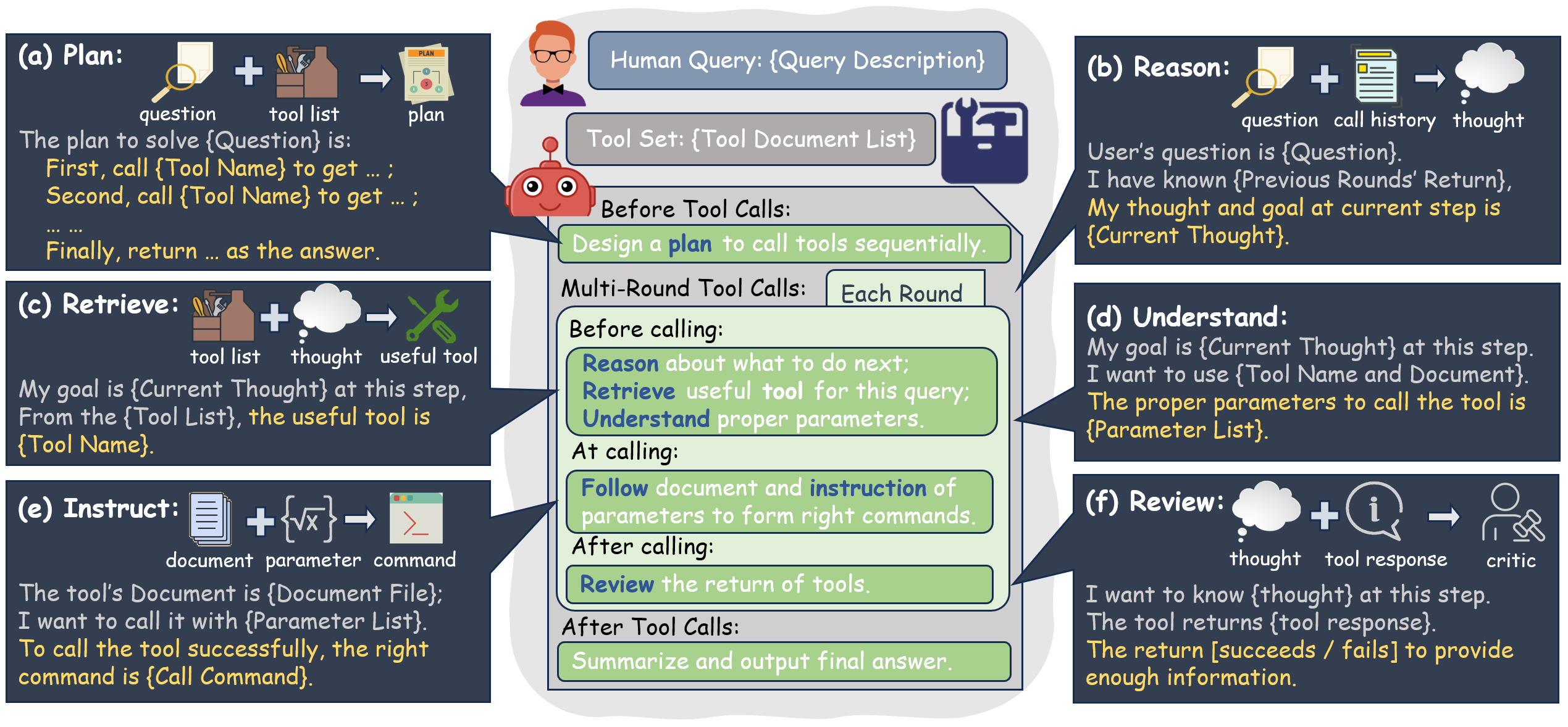
Evaluation Protocol
Tool utilization with LLMs touches upon multiple dimensions of capabilities. We deconstruct the tool-calling process into several key aspects, as depicted in Fig. 1. Initially, solving complex real-world problems frequently requires a multi-step approach to tool calling. This requires a robust planning ability (Fig. 1(a)) to develop a strategy for tool calling that guides subsequent actions.
The contexts in which tools are utilized can be intricate, and thus strong reasoning abilities (Fig. 1(b)) are essential to generating logical thoughts for the next steps. After generating a thought, selecting the appropriate tools from a given list demands effective retrieval skills (Fig. 1(c)). Additionally, integrating the correct parameters requires the understanding ability (Fig. 1(d)) to interpret tool documentation and corresponding thoughts. Finally, executing the tool-calling action mandates adept instruction following skills (Fig. 1(e)) to formulate precise requests for APIs. Each tool call executed by LLM must be evaluated to ensure the response meets the intended objective. This crucial evaluation is named the review ability (Fig. 1(f)).
In summary, T-Eval takes the six ability dimensions as mentioned above (planning, reason, retrieve, understand, instruct, and review) into consideration, measuring not only the overall performance of tool-utilization but also detailed scores.
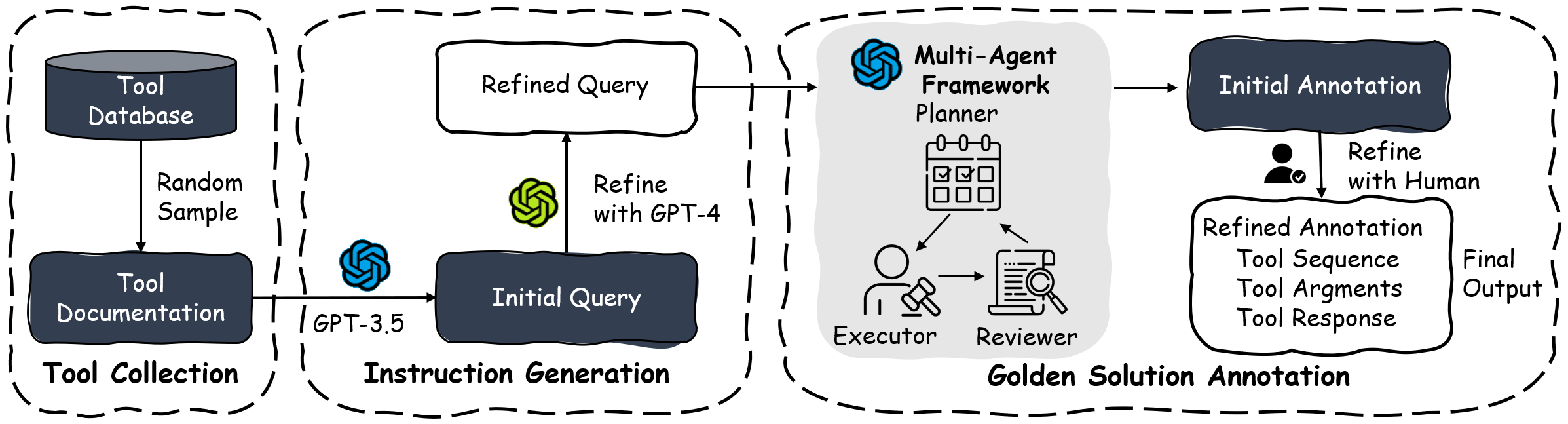
Figure 2. the data generation pipeline.
Data Generation Pipeline
The construction of T-Eval consists of three main phases: tool collection, instruction generation, and golden solution annotation. The overview of the construction is shown in Fig. 2. We follow two principles during the collection process:
- High Availability and Usage Rate: Considering that T-Eval is expected to cover most daily and practical use cases, we carefully select 1 ~ 2 tools for each specific domain, including Research, Travel, Entertainment, Web, Life, and Financials, resulting in 15 tools as our basic tool set.
- Complete Documentations: To reduce the failure of tool-calling cases caused by inadequate tool descriptions, which focus the evaluation attention on pure LLM abilities, we manually generate high-quality and detailed tool documentation for each tool.
Result
You can find the newest leaderboard of our T-Eval benchmark Here.
This webpage template was recycled from here.
Citation
@article{chen2023t,
title={T-Eval: Evaluating the Tool Utilization Capability Step by Step},
author={Chen, Zehui and Du, Weihua and Zhang, Wenwei and Liu, Kuikun and Liu, Jiangning and Zheng, Miao and Zhuo, Jingming and Zhang, Songyang and Lin, Dahua and Chen, Kai and others},
journal={arXiv preprint arXiv:2312.14033},
year={2023}
}