Critique ability are crucial in the scalable oversight and self-improvement of Large Language Models (LLMs). While many recent studies explore the critique ability of LLMs to judge and refine flaws in generations, how to comprehensively and reliably measure the critique abilities of LLMs is under-explored. This paper introduces CriticEval, a novel benchmark designed to comprehensively and reliably evaluate four key critique ability dimensions of LLMs: feedback, comparison, refinement and meta-feedback. CriticEval encompasses nine diverse tasks, each assessing the LLMs' ability to critique responses at varying levels of quality granularity. Our extensive evaluations of open-source and closed-source LLMs reveal intriguing relationships between the critique ability and tasks, response qualities, and model scales.
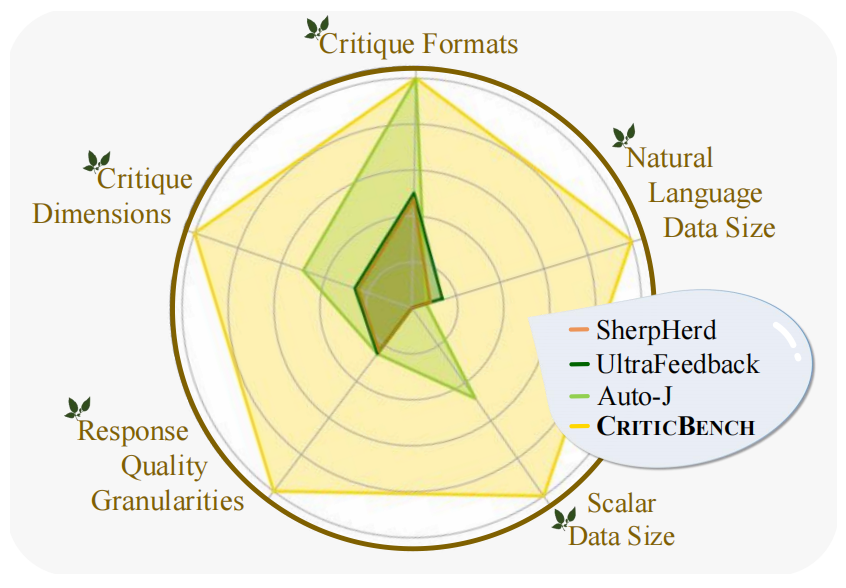
Figure 1. Comparison between CriticEval and previous works.
Introduction
CriticEval evaluate 9 tasks (translate, general chat, question answer, summary, harmlessness, math with chain-of-thought, math with program-of-thought, code with executions, code without executions) for 4 critique dimensions (Feedback, Comparison, Correction, Meta-Feedback) on 4 kinds of response qualities (low-quality, medium-quality, high-quality, correct). Besides, the objective and subjective scores are computed for each task and each critique dimensions.
Overall, CriticEval exhibits significant advantages over previous benchmarks on critique evaluation (Fig. 1), showing great diversity in response quality granularity, critique formats, critique dimensions, and data size, allowing deeper analysis of the LLMs' critique capabilities.
Data Generation Pipeline
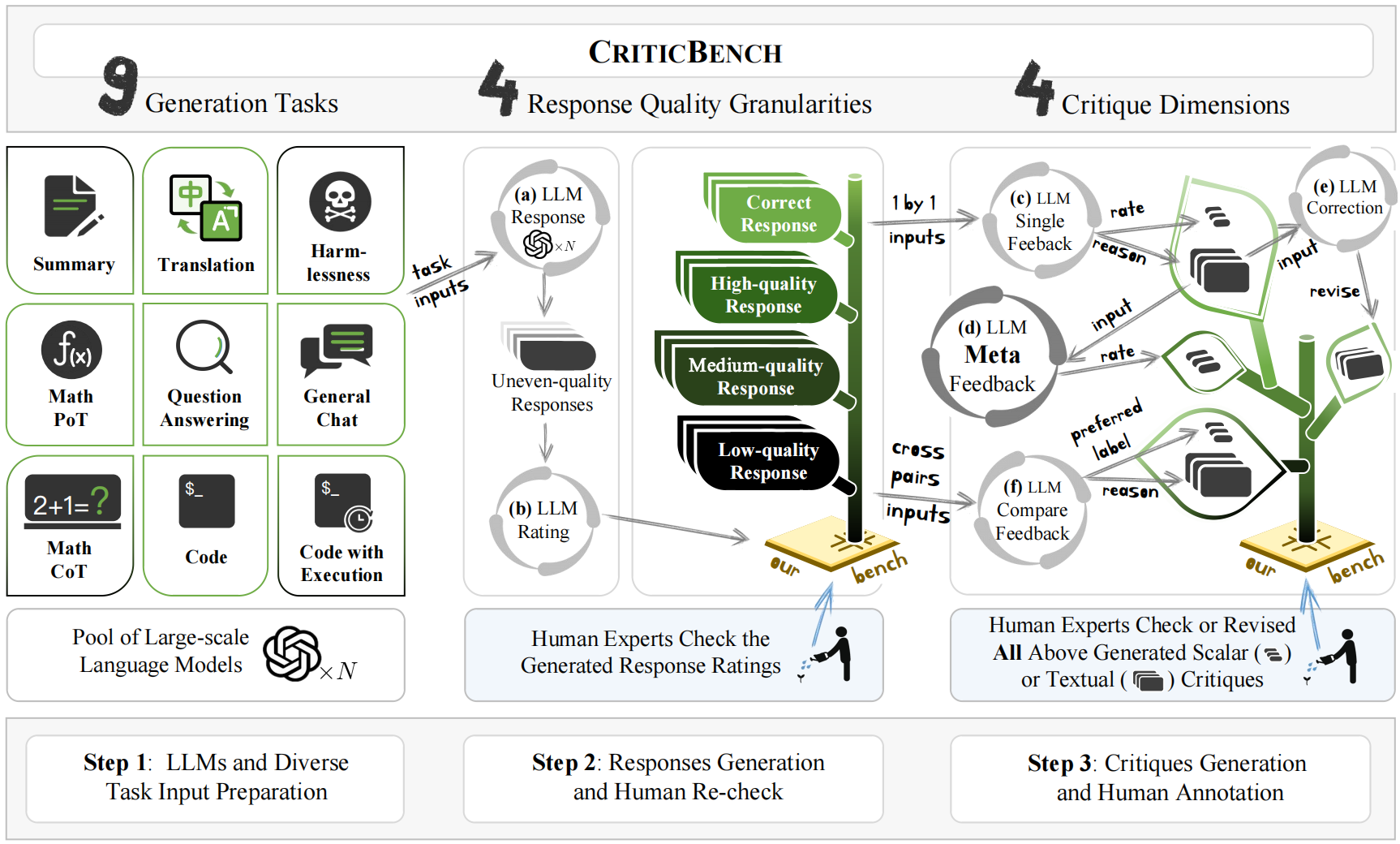
Figure 2. Overview and Construction Pipeline of CriticEval.
The human-in-the-loop construction of CriticEval are conducted. CriticEval consists of three main phases: instruction collection, response generation, and reference critique generation. The overview of the construction is shown in Fig. 2., and the details of each phase are described as follow:
Instruction collection: Instructions for 9 distinct tasks are collected to evaluate critique capabilities comprehensively (Step 1 in Fig. 2). Specifically, the benchmark includes three representative classical language tasks: summary, translation, and question-answering. Since a popular application of LLMs is to serve as a chatbot, where alignment is important to ensure the safe application of LLMs, we collect instructions from general chat scenarios and harmlessness cases to evaluate the LLMs' critique ability for alignment. Furthermore, the reasoning and code capabilities are also fundamental for augmenting LLMs as agents, another important and promising application of LLMs. Thus, we also collect instructions for math reasoning with chain-of-thought and program-of-thought, and coding with and without execution results. To ensure the difficulty of CriticEval, we only collect coding and math reasoning questions that some 70B LLMs cannot correctly answer.
Response Generation: For each collected instruction in each task, LLMs of different scales and capabilities are employed to generate responses with flaws, which naturally form responses of various qualities (Step 2 (a) in Fig. 2). To identify the quality of these responses efficiently, GPT-4 is utilized to initially assign quality ratings ranging from 1 to 7 (Step 2 (b) in Fig. 2.) then let human annotators meticulously review and adjust these scores. Subsequently, three responses with distinct quality differences for each instruction are chosen based on their human-varified quality scores, including low-, medium-, and high-quality responses.
Reference Critique Generation: After collecting instructions and the corresponding responses, we collect reference critiques on these responses to make the subjective evaluation more reliable, with the assistance of GPT-4, including the feedback, correction, comparison, and meta-feedback. Note that correction and meta-feedback critique dimensions are overlooked in previous works.
Result
You can find the newest subjective and objective leaderboards of our CriticEval.