CIBench: Evaluating Your LLMs with a Code Interpreter Plugin
Abstract
While LLM-Based agents, which use external tools to solve complex problems, have made significant progress, benchmarking their ability is challenging, thereby hindering a clear understanding of their limitations. In this paper, we propose an interactive evaluation framework, named CIBench, to comprehensively assess LLMs' ability to utilize code interpreters for data science tasks. Our evaluation framework includes an evaluation dataset and two evaluation modes. The evaluation dataset is constructed using an LLM-human cooperative approach and simulates an authentic workflow by leveraging consecutive and interactive IPython sessions. The two evaluation modes assess LLMs' ability with and without human assistance. We conduct extensive experiments to analyze the ability of 24 LLMs on CIBench and provide valuable insights for future LLMs in code interpreter utilization.
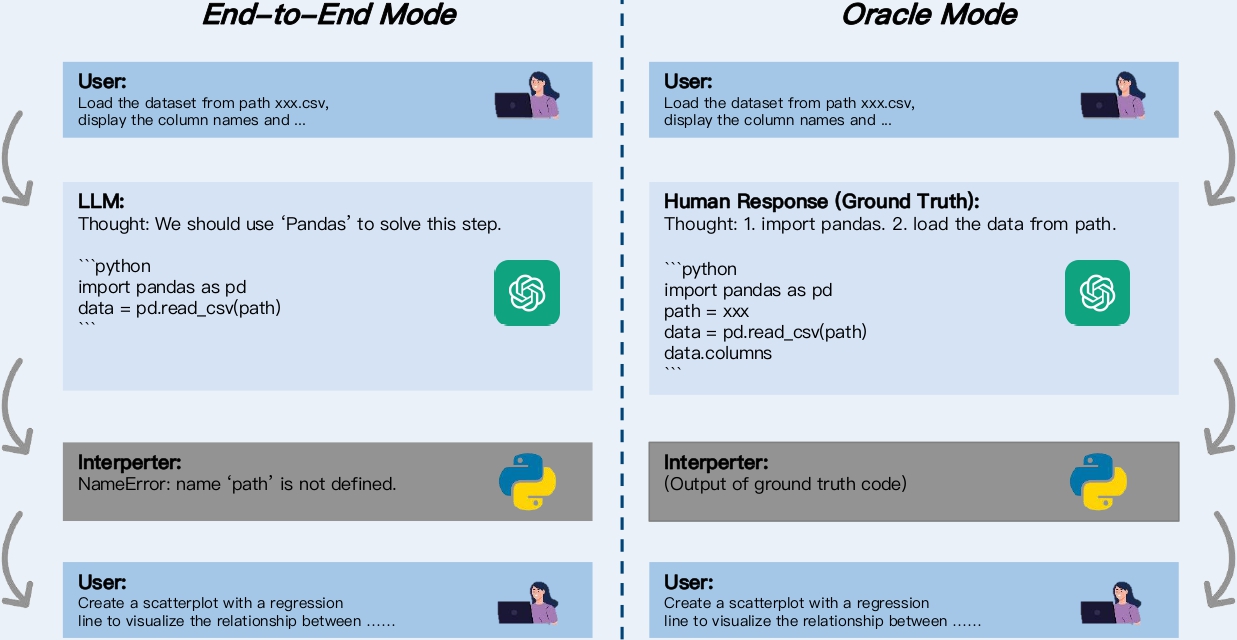
We propose two evaluation modes to benchmark LLM's ability w/ or w/o human assistance respectively. In end-to-end mode, the LLM addresses the user's question (bottom) within the context of its response, while in oracle mode, it answers the user's question (bottom) within the context of ground truth..
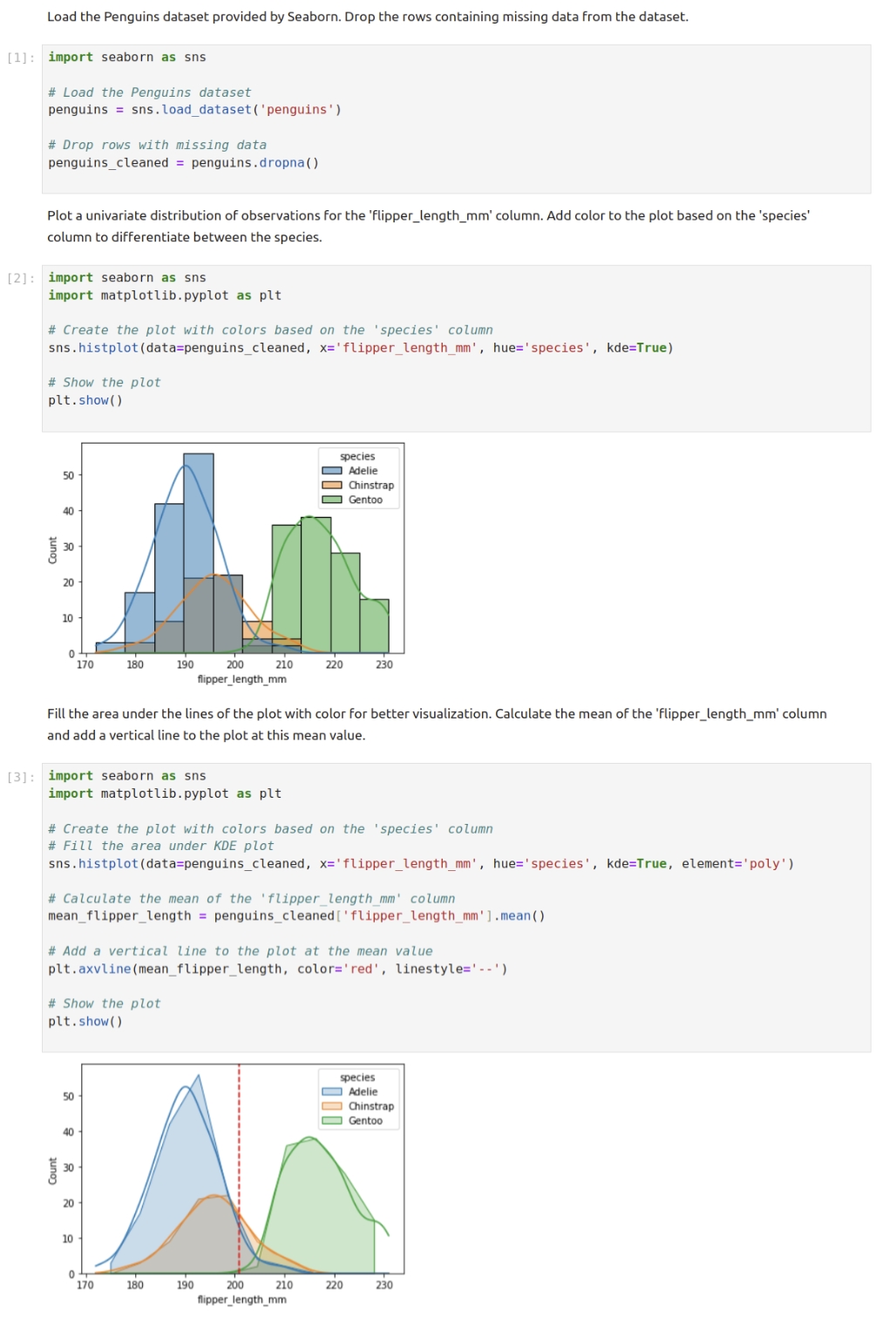
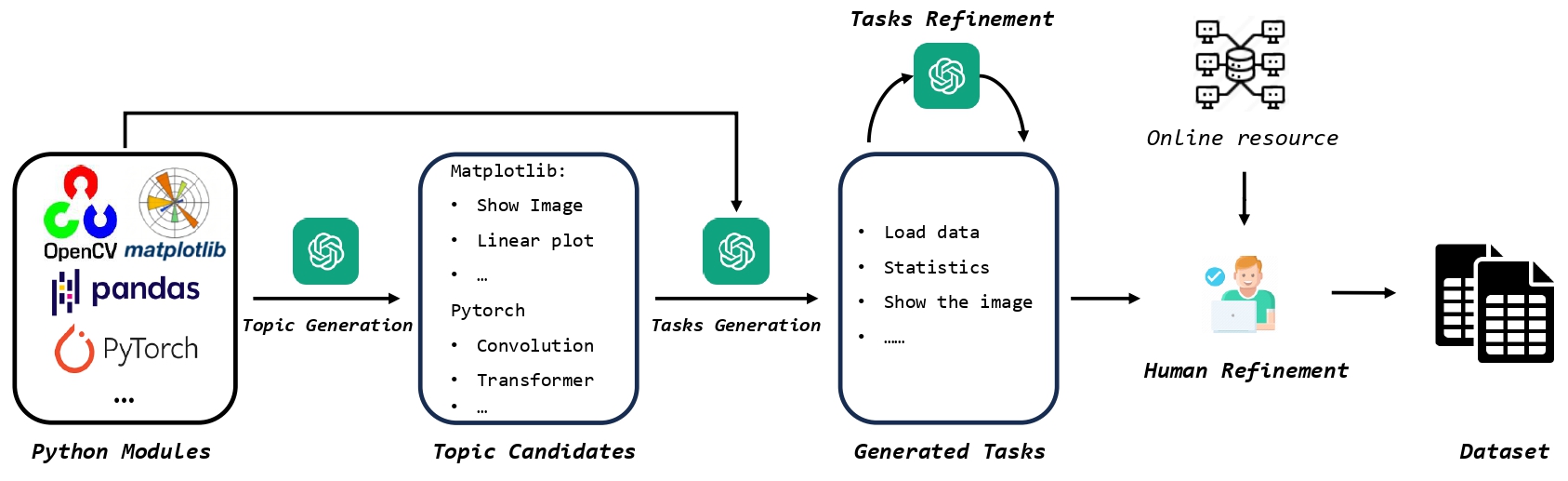
An example of CIBench. For any other dataset, we can repalce the dataset name and columns names. Therefore, template tasks can be used for different dataset file, thus greatly enlarge the CIBench. We will open-source the dataset later.
This webpage template was recycled from here.
Citation
@article{chen2023t,
title={CIBench: Evaluating Your LLMs with a Code Interpreter Plugin},
author={Songyang Zhang*, Chuyu Zhang*, Yingfan Hu*, Haowen Shen, Kuikun Liu, Ma Zerun, Fengzhe Zhou, Wenwei Zhang, Xuming He, Dahua Lin, Kai Chen},
year={2024}
}